Très souvent, lorsqu’une requête donnée traîne un peu, une solution pour l’optimiser consiste à s’attacher à positionner des index adéquats. Un élément important dans le design des index réside dans la notion d’index couvrants.
Dans cet article, nous nous appuierons sur la base d’exemple de SQL Server 2012, AdventureWorks2012, disponible ici.
Dans un premier temps, les colonnes candidates pour un index sont les colonnes utilisées pour filtrer les résultats de la requêtes. Ainsi, prenons la requête ci-dessous :
select PersonType,LastName,FirstName from Person.Person where PersonType='SP'
Lorsqu’on l’exécute, on obtient le plan d’exécution suivant :

On remarque un parcours complet de la table (Index Scan), ce qui au final donne un nombre de lectures assez élevé.
Table ‘Person’. Scan count 1, logical reads 3820, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Si l’on positionne désormais un index sur la colonne PersonType, on s’aperçoit qu’il est utilisé et que le nombre de pages lues chute de manière drastique. Jusqu’ici, tout va bien.
create index IX_Person_PersonType ON Person.Person(PersonType)
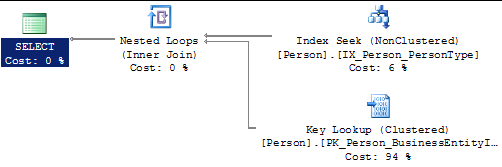
Table ‘Person’. Scan count 1, logical reads 53, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Mais lorsque le filtre ne restreint plus uniquement sur quelques enregistrements, le surcoût des opérations Key Lookup devient trop important.
Pour rappel, une recherche de clé (Key Lookup) correspond au fait d’aller chercher dans un autre index les colonnes manquantes (dans notre cas les colonnes LastName et FirstName) alors que l’on n’a à notre disposition que les colonnes présentes dans les feuilles de notre index non clustered (dans notre cas PersonType et BusinessEntityID).
Lorsque le nombre de recherches de clés (Key Lookup) devient trop important, le moteur SQL Server peut même décider d’aller chercher les données manquantes autrement que via un Key Lookup.
select PersonType,LastName,FirstName from Person.Person where PersonType='VC'
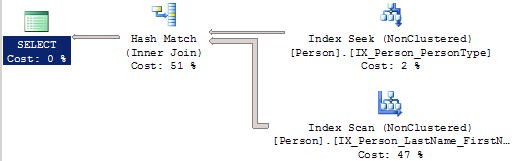
Le système préfère ici effectuer un scan complet d’un autre index pour obtenir les colonnes demandées. Le moteur s’appuie ici sur l’index non clustered dont le parcours est le moins coûteux, c’est-à-dire l’index dédié aux colonnes FirstName et LastName.
Si notre requête concerne d’autres colonnes, par exemple la colonne Demographics, le fonctionnement est différent. En effet, il n’y a pas d’index s’appuyant sur cette colonne. Au final, si la solution la moins coûteuse est celle passant par un Key Lookup (en comparaison avec un scan complet de l’index Clustered), même si cela nous oblige tout de même à avoir un nombre de lectures qui croit assez rapidement.
select PersonType,Demographics from Person.Person where PersonType='SC'
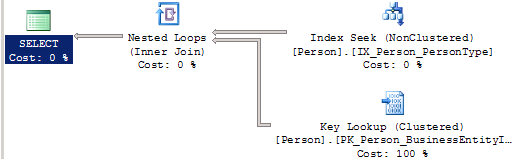
Table ‘Person’. Scan count 1, logical reads 2320, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Afin de réduire le coût d’une telle requête, une technique habituelle consiste à ajouter des colonnes aux index utilisés. Ainsi, dans le cas des colonnes LastName et FirstName, on pourrait ajouter les colonnes à l’index défini sur PersonType.
Mais lorsque la colonne requise est la colonne Demographics, il n’est pas possible d’ajouter cette colonne directement à l’index car son type de données, XML, n’est pas triable.
Néanmoins, SQL Server, depuis sa version 2005, nous permet d’ajouter des colonnes, même d’un type de données non triable, au niveau terminal des index (niveau auquel les pages sont appelées feuilles).
create index IX_Person_PersonType_Demographics ON Person.Person(PersonType) INCLUDE (Demographics)
Table ‘Person’. Scan count 1, logical reads 51, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
On constate effectivement qui le nombre de lectures est redevenue très faible, ce qui correspond donc à de bonnes performances pour la requête.
Ce type d’index, dédié à une ou plusieurs requêtes type et apportant toutes les colonnes requises par ces requêtes, est appelé index couvrant. Comme toujours avec les index, on a une amélioration des performances de lecture mais au détriment des performances lors des écritures.
Le mot clé INCLUDE permet de lister des colonnes qui ne seront positionnées que dans les niveaux terminaux de l’index. Même si ces colonnes incluses sont souvent indiquées au niveau des conseils liés aux index manquants, il faut toutefois faire attention à ne pas trop en abuser, car l’espace consommé peut rapidement augmenter (en dupliquant des données à outrance) et cela peut dégrader les performances liées aux modifications.
Bonjour Jean-Nicolas,
Il semblerait qu’il soit impossible d’inclure une colonne sur un index « PRIMARY KEY » non clustered.
Dans ce cas, je vois deux solutions :
– Ajouter la colonne comme une des clés de l’index – elle ne sera pas discriminante car les clés déjà présentes le sont, mais il y a peut-être un risque de performances lors de l’indexation d’une colonne « inutile à l’index »
– Remplacer l’index « PRIMARY KEY » par un index simple qui ne sera pas déclaré « PRIMARY KEY » mais qui pourra inclure la colonne supplémentaire. Avec cette solution, quel est le danger de ne pas avoir d’index « officiellement déclaré PRIMARY KEY » ?
Bonne journée.
Bonjour Jérôme,
Effectivement, il ne peut pas y avoir de colonne incluses dans une clé primaire.
Le fait de transformer la contrainte de clé primaire en index unique permet effectivement d’ajouter des colonnes incluses, mais n’est possible que si la table n’est pas référencée par une clé étrangère.
Si la clé primaire est réellement utile dans ce rôle (référence d’une clé étrangère), alors il convient d’ajouter un autre index qui, lui, contiendra les colonnes nécessaires à la couverture des requêtes fréquentes.
JN.