Quelle idée d’écrire un article pour expliquer comment compter le nombre d’enregistrements dans une table ? Tout le monde sait répondre !
SELECT COUNT(*) FROM MaTable
Et bien non, justement ! Il y a bien plus performant …
En effet, lorsque l’on compte simplement les lignes d’une table avec la syntaxe SELECT COUNT(*), le moteur choisit le plus petit index non filtré sur cette table, et le parcourt entièrement en comptabilisant les lignes rencontrées.
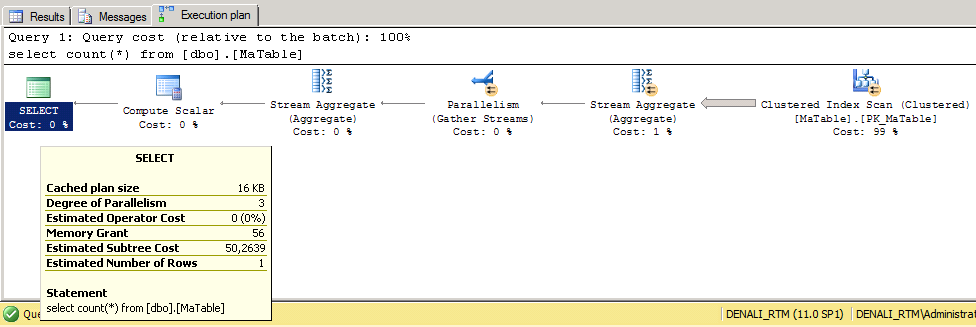
On constate donc au final un coût qui peut être non négligeable. (l’exemple ci-dessus s’appuie sur une table contenant un million d’enregistrements).
Et de plus, si quelqu’un a commencé (mais pas terminé) une transaction qui effectue une modification dans cette table, on peut se retrouver bloqué (voir la notion ACID et les transactions).
Il faut savoir qu’en arrière plan, SQL Server met à disposition des vues systèmes qui permettent de consulter entre autres choses l’ensemble de la structure d’une base de données, et notamment le nombre d’enregistrements dans chaque index.
Il suffit donc de prendre en compte au choix :
- l’index ayant pour identifiant 0, c’est-à-dire le segment de données, pour les cas où la table n’a pas d’index Clustered
- l’index ayant pour identifiant 1, c’est-à-dire l’index clustered, lorsque celui-ci existe.
On obtient la requête suivante :
select sum(p.rows)
from sys.partitions p
where p.object_id=object_id('[dbo].[MaTable]') and index_id in (0,1)
Remarque : on utilise l’agrégat (SUM) afin de prendre en compte les tables partitionnées (dont les données sont sur plusieurs partitions).
Le plan d’exécution de cette requête, et surtout son coût, n’a absolument rien à voir !
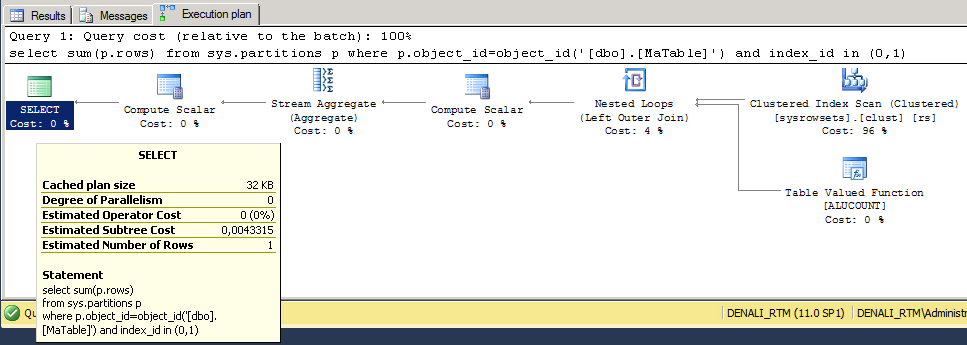
Au final, on constate bien que le fait de compter le nombre de lignes d’une table peut paraître trivial mais que la force brute n’est pas toujours la meilleure solution (dans le cas présent, le coût de la requête varie dans un ratio supérieur à 10 000 !).
Récemment, j’ai eu à intervenir sur un serveur sur lequel c’était ce type de requête qui étaient les plus coûteuses. Il convient donc de ne pas oublier ce « petit » raccourci …
Bonjour,
Vous auriez dû intituler votre article : « Nombre de ligne APPROXIMATIF d’une table ».
En effet, la documentation officielle (http://msdn.microsoft.com/fr-fr/library/ms175012.aspx – sys.partitions (Transact-SQL) – SQL Server 2012), vous donne la définition de la colonne rows que voici :
rows | type bigint | Indique le nombre APPROXIMATIF de lignes dans cette partition.
Bonjour BinaryDrink,
Merci pour votre remarque très pertinente.
Le nombre de lignes retourné est effectivement d’une certaine façon approximatif, mais cela reste dans un environnement de production très souvent suffisamment juste et surtout préférable à un COUNT(*) :
– la notion d’approximation est entre autres choses liée à la gestion des transactions (une valeur est immédiatement retournée, même si des transactions modifiant le nombre de lignes sont en cours). Dans notre contexte, c’est justement un comportement recherché, afin de ne pas être perturbé par les transactions en cours (et aussi afin de ne pas les perturber)
– cette valeur peut éventuellement être altérée manuellement via la commande UPDATE STATISTICS, à travers une option non documentée ROWCOUNT. Cette pratique, non recommandée en production, permet de simuler certaines cardinalités afin d’observer les plans d’exécutions qui en découlent (dans le contexte d’une simulation de charge)
JN.
Merci BinaryDrink !
Tout le monde sait répondre avec un résultat exact grâce à SELECT COUNT(*) mais seul Nicolas a trouvé une réponse avec un résultat … approximatif qu’il a essayé de justifier. Moi, j’ai l’impression de me faire avoir par un gros titre accrocheur dans les magazines.
Je crois que Nicolas doit creuser davatage encore avant de publier un prochain article.
Cordialement.
Bonjour Toto,
Avez-vous déjà eu l’occasion de chercher à situer le nombre de lignes dans une « grosse » table (plusieurs dizaines de millions d’enregistrements, voir plus encore), avec un besoin fonctionnel qui n’en est pas à 1 enregistrement près ? Avez-vous déjà eu l’occasion de voir un SELECT COUNT(*) dans le trio de tête des opérations les plus gourmandes en total d’IO sur un serveur de production ? Personnellement, je peux répondre oui à ces deux questions.
Avez-vous déjà constaté une différence pour une grosse table entre le compteur dans la table sys.partitions (hormis valeur bricolée via UPDATE STATISTICS) et le résultat d’un SELECT COUNT(*), une fois les locks potentiels éventuellement résolus par une attente ou par un hint ? Personnellement, non, mais j’avoue ne pas avoir systématiquement cherché à comparer.
Au-delà de cela, pour reprendre une image dont je ne revendique pas la paternité, lorsque l’on dit que la température au cœur du Soleil est de 15 millions de degrés, est-il vraiment judicieux de s’interroger pour savoir s’il s’agit de degrés Celsius ou de Kelvin ? Si vous pensez que oui, alors je vous laisse libre d’utiliser sur vos serveurs de production tous les SELECT COUNT(*) que vous voudrez, et je vous conseille de les utiliser accompagnés du hint SERIALIZABLE.
D’autre part, si vous avez l’idée de points techniques qui vous paraitraient plus intéressants, je reste disponible et vous invite à m’en faire part.
Cordialement.
Jean-Nicolas.
Bonjour,
Je sais que cet article a un an ou plus. Je suis tombé dessus par hasard en cherchant autre chose.
Moi je le trouve très intéressant et la remarque de toto n’est effectivement pas justifié car l’approximativement est bien là pour dire que le nombre renvoyé est juste sauf transaction en cours. Contrairement au count qui lui donne un résultat toutes transactions effectuées d’où des blocages possibles. Mais même un count est approximatif car dans le dixième de seconde suivant le résultat donné il peux très bien y avoir eu d’autre modification et donc une nouvelle valeur.
Certe je n’ai pas eu l’occasion de travailler sur des bases suffisamment importantes mais même avec quelques centaines de millier d’enregistrement, je vais vérifier si les count peuvent avoir un impacte.
Moi je vous remercie pour cet article qui donne des pistes à explorer pour optimiser les serveurs de base de données.
Robert
+1