J’ai tendance à répéter à l’envi que les opérations dans SQL Server doivent être effectuées au maximum en ensembliste plutôt qu’en unitaire. Cela concerne aussi les transactions qui, à partir du moment où cela répond au fonctionnel, ne doivent pas être d’une granularité trop fine.
Tout comme il vaut mieux modifier une fois mille enregistrements que mille fois un enregistrement, il vaut mieux avoir une transaction de mille instructions que mille transactions de une instruction.
Pour montrer les effets de trop nombreuses transaction, je vais considérer une table dans laquelle je dois insérer 50000 enregistrements et comparer l’action de ces nombreuses insertions avec une transaction par insertion d’une part et avec une transaction globale d’autre part.
Tout d’abord, plantons le décor, en créant une base et une table. Nous affecterons notamment à la base un fichier de journal de transactions suffisamment volumineux pour que le test ne soit pas perturbé pas des grossissements automatiques.
USE master;
GO
IF EXISTS( SELECT *
FROM sys.databases
WHERE name = 'TestLog'
)
BEGIN
DROP DATABASE TestLog
END;
GO
CREATE DATABASE TestLog;
GO
ALTER DATABASE TestLog SET RECOVERY SIMPLE;
GO
ALTER DATABASE TestLog MODIFY FILE( NAME = N'TestLog_log' , SIZE = 1024000 KB , MAXSIZE = UNLIMITED , FILEGROWTH = 102400 KB
);
GO
USE TestLog;
GO
CREATE TABLE Donnees( Id int PRIMARY KEY
IDENTITY ,
Donnee varchar( 20
)
);
GO
Ensuite, mettons la base en mode de récupération complet, afin de se prémunir des purges du journal de transactions, et de bien pouvoir consulter toutes les informations écrites dans ce journal lors du test.
CHECKPOINT; ALTER DATABASE TestLog SET RECOVERY FULL; GO
Ensuite, lançons un script qui, en boucle, effectuera 50000 insertions en base. Préalablement, on remettra à zéro le compteur des attentes internes SQL Server. A la fin du processus, on mesurera la durée du test, les attentes principales, ainsi que les principaux types d’opérations enregistrées dans le journal de transactions avec la volumétrie que cela représente.
DBCC SQLPERF( "sys.dm_os_wait_stats" , CLEAR
);
SET NOCOUNT ON;
DECLARE
@t0 datetime = GETDATE(
);
DECLARE
@i int;
SET @i = 0;
WHILE @i < 50000
BEGIN
INSERT INTO Donnees( Donnee
)
VALUES( 'Test'
);
SET @i+=1;
END;
SELECT DATEDIFF( ms , @t0 , GETDATE(
)
)AS [Durée opération];
WITH [Waits]
AS ( SELECT wait_type ,
wait_time_ms / 1000.0 AS WaitS ,
(wait_time_ms - signal_wait_time_ms) / 1000.0 AS ResourceS ,
signal_wait_time_ms / 1000.0 AS SignalS ,
waiting_tasks_count AS WaitCount ,
100.0 * wait_time_ms / SUM( wait_time_ms
)OVER(
)AS Percentage ,
ROW_NUMBER(
)OVER( ORDER BY wait_time_ms DESC
)AS RowNum
FROM sys.dm_os_wait_stats
WHERE wait_type NOT IN( N'CLR_SEMAPHORE' , N'LAZYWRITER_SLEEP' , N'RESOURCE_QUEUE' , N'SQLTRACE_BUFFER_FLUSH' , N'SLEEP_TASK' , N'SLEEP_SYSTEMTASK' , N'WAITFOR' , N'HADR_FILESTREAM_IOMGR_IOCOMPLETION' , N'CHECKPOINT_QUEUE' , N'REQUEST_FOR_DEADLOCK_SEARCH' , N'XE_TIMER_EVENT' , N'XE_DISPATCHER_JOIN' , N'LOGMGR_QUEUE' , N'FT_IFTS_SCHEDULER_IDLE_WAIT' , N'BROKER_TASK_STOP' , N'CLR_MANUAL_EVENT' , N'CLR_AUTO_EVENT' , N'DISPATCHER_QUEUE_SEMAPHORE' , N'TRACEWRITE' , N'XE_DISPATCHER_WAIT' , N'BROKER_TO_FLUSH' , N'BROKER_EVENTHANDLER' , N'FT_IFTSHC_MUTEX' , N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP' , N'DIRTY_PAGE_POLL' , N'SP_SERVER_DIAGNOSTICS_SLEEP'
)
AND wait_time_ms
>
0.
)
SELECT W1.wait_type AS WaitType ,
CAST( W1.WaitS AS decimal( 14 , 2
)
)AS Wait_S ,
CAST( W1.ResourceS AS decimal( 14 , 2
)
)AS Resource_S ,
CAST( W1.SignalS AS decimal( 14 , 2
)
)AS Signal_S ,
W1.WaitCount AS WaitCount ,
CAST( W1.Percentage AS decimal( 4 , 2
)
)AS Percentage ,
CAST( W1.WaitS / W1.WaitCount AS decimal( 14 , 4
)
)AS AvgWait_S ,
CAST( W1.ResourceS / W1.WaitCount AS decimal( 14 , 4
)
)AS AvgRes_S ,
CAST( W1.SignalS / W1.WaitCount AS decimal( 14 , 4
)
)AS AvgSig_S
FROM
Waits AS W1 INNER JOIN Waits AS W2
ON W2.RowNum
<=
W1.RowNum
WHERE W1.WaitCount
>
0.
GROUP BY W1.RowNum ,
W1.wait_type ,
W1.WaitS ,
W1.ResourceS ,
W1.SignalS ,
W1.WaitCount ,
W1.Percentage
HAVING SUM( W2.Percentage
) - W1.Percentage
<
95; -- percentage threshold
GO
SELECT TOP 10 Operation ,
COUNT( *
)AS [Nb opérations] ,
SUM( [Log Record Length]
)AS [Volume (bytes)]
FROM fn_dblog( NULL , NULL
)
GROUP BY Operation
ORDER BY SUM( [Log Record Length]
)DESC;
SELECT SUM( [Log Record Length]
)AS [Volume écriture Log]
FROM fn_dblog( NULL , NULL
);
GO
Les résultats parlent d’eux-mêmes :
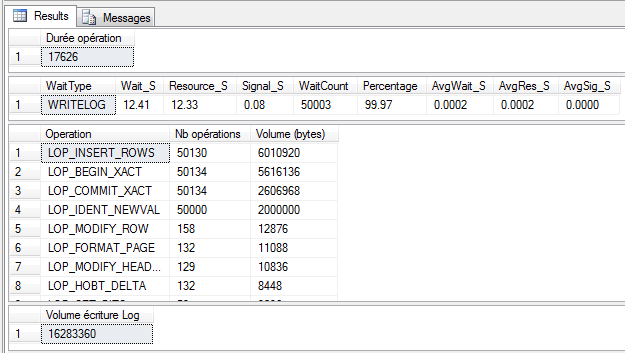
L’insertion dure 17,6 secondes, et 99,97 du temps est passé sur des attentes WRITELOG, c’est-à-dire des écritures dans le journal de transactions. On a 50134 opérations de début de transaction et autant de fins de transactions. Réunis, les enregistrements de ces deux types d’opérations représentent la moitié de la volumétrie insérée.
Mais pourquoi a-t-on autant de transactions, alors que nous n’en avons explicitement ouvert aucune ? Et bien justement parce que lorsqu’aucune transaction n’est explicitement ouverte, alors chaque instruction se retrouve encadrée dans une transaction implicite. Nous avons donc 50000 transactions implicites, plus quelques transactions internes liées à la mise à jour des index (ajouts de pages de stockage, …).
Au final, cela représente 16Mo de journal, écrit petit morceau par petit morceau (une transaction n’est validée que lorsque le système de stockage confirme avoir écrit les informations correspondantes dans le journal).
Maintenant, cherchons à modifier le script en intégrant l’ensemble des 50000 insertions dans une seule et même transaction.
DECLARE
@i int;
SET @i = 0;
BEGIN TRANSACTION;
WHILE @i < 50000
BEGIN
INSERT INTO Donnees( Donnee
)
VALUES( 'Test'
);
SET @i+=1;
END;
COMMIT TRANSACTION;
La différence en termes de durée d’exécution et d’attentes est flagrante :
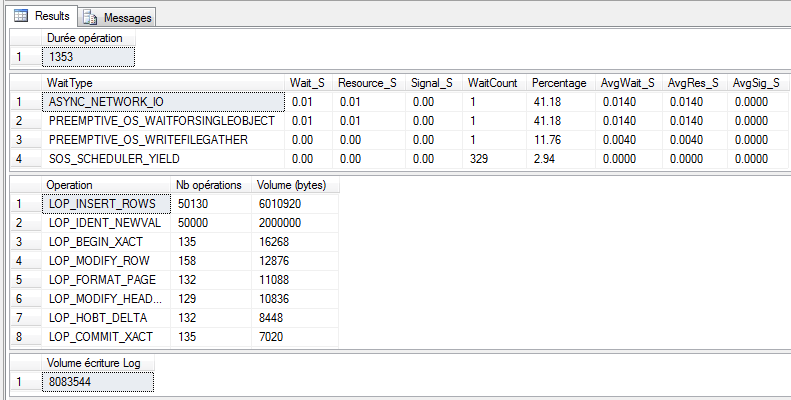
Nous avons totalement gommé les attentes WRITELOG (étant donné que l’on a seulement demandé au système de faire une écriture massive dans le journal, au lieu de n micro-écritures), et la durée totale du traitement a été réduite dans un ratio supérieur à 10 !
Il est donc au final très important de comprendre que de multiples petites transactions peuvent très fortement ralentir un système, et que si on peut regrouper des écritures multiples dans une transaction englobante, il ne faut surtout pas s’en priver…